소개
공분산은 공+분산이 합쳐진 단어인데, 여기서 공(共)은 한자로 (함께, 여럿)을 뜻하는 공입니다. 따라서 공분산은 여럿으로 구한 분산을 의미합니다. 즉, 변수 하나로 구한 분산이 아니라 변수 여럿으로 구한 분산입니다. 결론부터 말하면 확률변수 '둘'로 구한 분산 값입니다. 그렇다면 공분산에 대한 이야기를 하기 전에 분산의 정의에 대해 짚고 넘어가겠습니다.
분산의 정의
어떤 변수 X의 분산은 아래와 같이 정의됩니다.

이때 만약에 대문자 X가 이산확률변수이고, 각 원소의 발생 확률이 같은 경우 아래와 같이 구합니다.

이산확률변수란?
확률변수 X가 취할 수 있는 값이 유한하기 때문에 셀 수 있는 확률변수이다. 예를 들어 '한 개의 동전을 두 번 던질 때 옆면이 나오는 횟수'와 '한 개의 주사위를 두 번 던질 때 눈금의 합'을 확률변수들로 삼으면, 이 확률변수들은 이산 확률변수이다. 확률변수가 취할 수 있는 값이 유한하기 때문이다.
연속 확률변수란?
확률변수 X가 취할 수 있는 값이 어떤 범위에 속하는 모든 실수로 무한하기 때문에 셀 수 없는 확률변수이다. 예를 들어 귤이 100개 들어있는 상자가 있는데 그 안에 있는 귤의 무게를 확률변수로 삼으면, 이 확률변수는 연속 확률변수이다. 확률변수가 취할 수 있는 값은 50g 이상 150g 이하에서 연속적으로 존재하기 때문이다. 10g, 20g, 30g 이런 식으로 결코 딱딱 안 떨어질 것이다. 아마도 101g, 97g, 95.8g, 102.1g 이런 식으로 값이 존재할 것이다.
또는 만약에 대문자 X가 이산 확률변수이고, 각 원소의 발생 확률이 다른 경우 아래와 같이 구합니다.

또는 만약에 대문자 X가 연속 확률변수인 경우 아래와 같이 구합니다.

조금 더 자세하게 분산의 정의가 왜 저렇게 만들어지는에 대해 수식적으로 접근하고 싶으시면 아래에 링크를 참고해주세요.
분산 - 위키백과, 우리 모두의 백과사전
빛의 분산에 대해서는 분산 (광학) 문서를 참고하십시오. 평균은 같지만 분산은 다른 두 확률 분포. 빨간색 분포는 100의 평균값과 100의 분산값을 가지고, 파란색 분포는 100의 확률값과 2500의 분
ko.wikipedia.org
공분산의 의미
공분산을 아래와 같이 정의를 해보았는데 의미는 무엇일까요? (이때 확률변수 X와 Y가 서로 종속인 데이터이다.)

만약 X와 Y가 서로 독립인 데이터라면, 위 식은 아래와 같이 변합니다.

서로 독립인 X, Y은 결국 각각 따로 기대치를 취하여 곱한 것과 같아 지기 때문에 정확하게 공분산이 0이 됩니다. 그렇다면 다시 두 변수가 서로 대응되는 상황(종속)을 생각해보면 X와 Y가 짝을 이루고 있다고 합시다. 그러면 아래와 같이 vector가 만들어지고
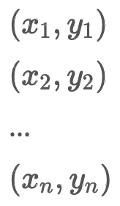
이때, 공분산은 아래와 같이 계산됩니다.
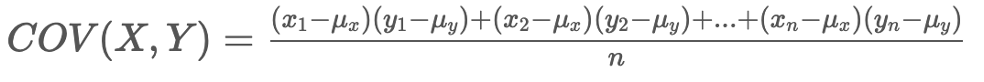
분자의 첫 항을 살펴보면
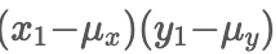
위 식으로 우리는 몇 가지 성질을 쉽게 알아낼 수 있습니다.
1) x1이 x의 평균보다 크고, y1도 y의 평균보다 크다면 위 값은 양수가 됩니다.
2) x1이 x의 평균보다 작고, y1도 y의 평균보다 작다면 위 값은 양수가 됩니다.
3) x1이 x의 평균보다 크고, y1도 y의 평균보다 작다면 위 값은 음수가 됩니다.
4) x1이 x의 평균보다 작고, y1도 y의 평균보다 크다면 위 값은 음수가 됩니다.
즉, x1과 y1이 평균에서 멀수록 위 값의 절댓값이 커집니다. 그렇다면 그래프로 생각하면 어떻게 될까요?
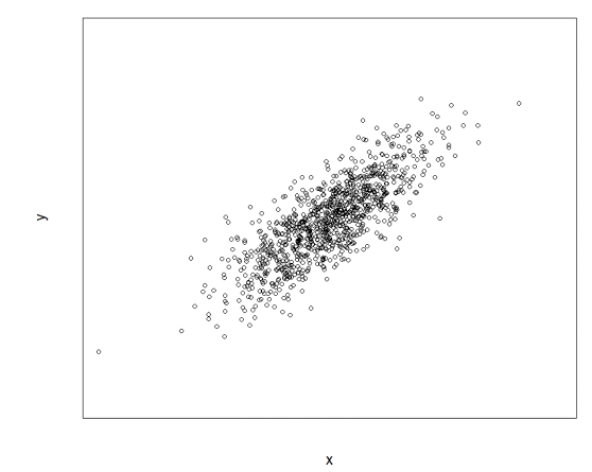
만약 공분산의 값이 양수라면
1. x가 평균보다 클 때 y가 평균보다 크다
2. x가 평균보다 작을 때 y가 평균보다 작다.
(x, y)에 대한 산점도를 그래프로 표현하면 아래와 같이 우상향 그래프를 나타낼 것입니다.
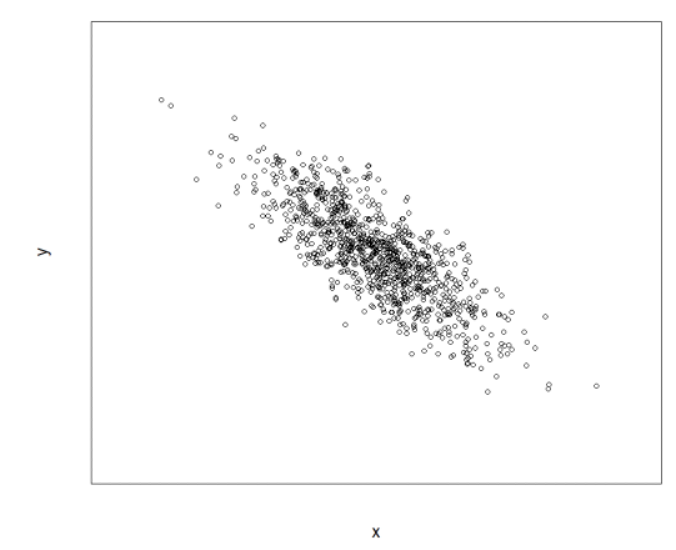
만약 공분산의 값이 음수라면
3. x가 평균보다 클 때 y가 평균보다 작다.
4. x가 평균보다 작을 때 y가 평균보다 크다.
(x, y)에 대한 산점도를 그래프로 표현하면 아래와 같이 우하향 그래프를 나타낼 것입니다.
결론
공분산(covariance)은 두 개의 확률변수의 상관 정도를 나타내는 값이다.
공분산의 한계
공분산은 크기와 부호를 갖는데 공분산의 부호는 위 그래프를 통해 알 수 있듯이 두 변수의 분포상태를 알려줍니다. 그렇다면 공분산의 크기는 어떤 역할을 할까요? 만약 단위(Unit)가 같은 데이터들의 공분산을 비교한다면, 공분산이 클수록 얇고 길게 분포한고 있다고 할 수 있습니다. 하지만 단위가 다른 데이터들 사이의 비교는 의미가 없습니다. 즉, 공분산은 단위에 영향을 받습니다.
확률변수가 큰 값을 다룬다면 공분산도 커지고 , 작은 확률변수 값을 다룬다면 공분사도 작아지겠지요.
예를 들어 키(height) 데이터로 구한 공분산과 시력 데이터로 구한 공분산 데이터가 있다고 합시다. 이때 두 데이터의 분포 형태가 동일하다고 해도 키 데이터의 공분산이 더 큽니다. 따라서 서로 다른 크기를 갖는 공분산들의 표준화가 필요하고, 이런 공분산을 표준화한 값이 피어슨 상관계수입니다. 피어슨 상관계수에 대한 이야기는 다음 포스트 때 올리도록 하겠습니다.
'Machine learning' 카테고리의 다른 글
| Linear Regression (0) | 2021.09.22 |
|---|---|
| Random Forest (0) | 2021.09.20 |
| Decision Tree (0) | 2021.09.19 |
| correlation coefficient (피어슨 상관계수) (0) | 2021.08.24 |
| Linear kalman filter (LKF) (0) | 2021.08.08 |