What is Decision tree?
결정 트리는 분류(Classification)와 회귀(Regression) 모두 가능한 지도 학습 모델 중 하나입니다. input 데이터들에서 우리가 원하는 데이터들을 예측 가능한 규칙들로 하나하나 분기(branch)로 만들어 Yes or No에 대한 의사결정을 내리는 구조이기도 합니다. 마치 그 구조가 '나무'와 같다고 해서 'Decision tree'라고 불립니다.
Decision tree는 Non-leaf node(branch), leaf node 만으로 구성되어 있는데, 아래의 그림을 보시면 조건식(ex: x < a)이 있는 부분이 branch(non-leaf node)이고 더이상 조건식에 들어갈 수 없는 데이터(ex: w)들은 하나의 leaf입니다.

조금 더 확실하게 말하면 이렇게 표현 할 수 있습니다.
Non-leaf node - branch (feature conditional expression)
Leaf node - classification
Decision tree를 활용한 스팸 메일 필터
이제 위에 설명한 Decision tree를 활용한 간단한 예시를 다뤄보도록 하겠습니다. 우리의 메일함은 365일 지금 이 순간에도 끔찍한 스팸 메일들의 공격을 받고 있습니다. 이런 스팸 메일들을 걸러내려면 어떻게 해야 할까요? 생각해보면 스팸 메일마다 공통적으로 쓰는 단어, 문장 혹은 링크 등등 여러 가지에 대한 정보를 우리는 알 수 있습니다. 이제부터 이 각각의 정보들을 Feature라고 부르고 이것들이 모여있는 집합을 Feature vector라고 부르겠습니다.
이때 프로그램을 조금이라도 다뤄본 사람들은 문득 이런 생각이 들수도 있습니다. 이게 if-then이랑 다를게 뭐야? 조건식 마다 특정 Feature들을 걸러내게 하면 그게 Decision tree 아니야?라는 생각을 할 수 있습니다. 따지고 보면 의미상 Input data에 대한 조건식을 통해 classification이 잘 이루어지니 그것도 Decision tree라고 할 수 있지요.
하지만 if-then 방법은 단순히 Traditional programming 방식이고 이 방식의 문제는 그 룰에 따라 코드의 길이는 기하급수적으로 늘어나 hard-code 룰이 되어버리는 문제점이 있습니다. 그래서 Machine learning 이라는 기법이 생기고 ML 기반의 Decision tree의 구조는 하드 코딩을 하지 않고도 데이터 기반의 규칙을 얻을 수 있습니다. 이제부터 그 규칙을 어떻게 얻는지 이야기를 시작해보겠습니다.
전에 우리는 각각의 정보들을 Feature 라고 정의를 했는데, 먼저 메일에 대한 피쳐를 정의해보겠습니다. 몇 가지 추려보면
| feature vector | feature.1 | feature.2 | feature.3 | feature.4 |
| words | attached files | links | malicious words |
단어의 수, 첨부 파일, 링크, 악의적인 단어 등등이 있습니다. 각 메일에 대한 저 feature들이 얼마나 들어있는지 예를 들어보겠습니다.
| words | attached files | links | malicious words | spam | |
| mail 1 | 256 | 0 | 3 | 7 | 1 (YES) |
| mail 2 | 56 | 1 | 0 | 3 | 0 (No) |
| mail 3 | 24 | 1 | 0 | 1 | 0 |
| mail 4 | 672 | 0 | 0 | 0 | 0 |
이렇게 특정 feature들을 가지고 spam인지 아닌지를 분류를 해야하는데 feature의 값이 단순하게 숫자가 아닌 다른걸로도 표현이 가능합니다. 신용대출에 대한 예시로 들어보면
| credit | term | Income | Age | Ioan | |
| Person 1 | Fair | 3years | High | <= 30 | risky |
| Person 2 | Fair | 3years | High | <= 30 | risky |
| Person 3 | Excellent | 3years | High | > 50 | safe |
| Person 4 | Poor | 5years | Low | 31...50 | safe |
그렇다면 이런 트리구조 즉, 브런치(feature..credit, term, income, age)들을 어떤 순서대로 구성할래? 에 대한 문제를 먼저 풀어야 합니다.
Decision Tree Construction
트리를 만드는 기본적인 아이디어는 greedy & recursive approach 에서부터 시작합니다. greedy는 말 그대로 '탐욕적이다' 라는 의미로 Decision tree에서는 가장 좋은 feature 1개 만을 선택하는 역할을 합니다. 여기서 가장 좋은 feature란 현재 들어오는 Input data들을 가장 classification을 잘하는 feature를 의미합니다.
이후에 recursive 즉, 나눠진 문제에서 다시 자기 자신을 호출하여 greedy한 방식으로 나눠진 데이터들을 또 가장 잘 classification을 잘하는 feature 1개를 고릅니다. 이렇게 더 이상 분류가 되지 않을때까지 무한 반복을 하게 됩니다.

하지만 이때 우리는 현재 들어와있는 input data에 대한 최적화 decision tree를 만들기 때문에 이는 자칫 Overfitting이 99% 발생할 수 있습니다. (Overfitting에 대한 자세한 이야기는 본 포스팃 마지막 부분에 적어보도록 하겠습니다.) 오버 핏팅이 될 경우 오히려 현재 t 시간대의 input 데이터 말고 다른 시간대의 예를 들어 t+3 이후의 input 데이터에 대한 분류는 잘 이루어지지 않습니다.
그렇기 때문에 이를 방지하기 위한 여럿 알고리즘들이 나왓고 대표적인 알고리즘 세 가지에 대한 설명을 해보겠습니다.
Algorithms
1. ID3 : entropy
2. C4.5 : Gain Ratio
3. CART : Gini index
위 세가지 알고리즘의 Comman idea가 두 가지 있는데 알고리즘을 살펴보기 전에 간단하게 무엇이 있는지 알아보겠습니다.
Comman idea
1. 각각의 feature(F)들은 얼마나 more homogeneous 한가 혹은 less heterogeneous하게 데이터들을 분류하였는가?

- 이때 가장 좋은 feature는 입력 데이터들을 호모 지니어스 하게 분류하는 feature로 선택됩니다.
2. Information Gain이 얼마인가?
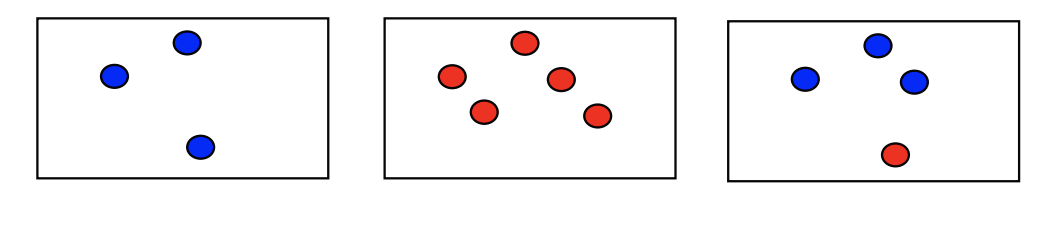
- 이제부터 Gain 이라는 단어가 나오는데 Gain을 계산하기 위해서 먼저 Entropy라는 단어부터 알아야 합니다. Entropy는 각각의 입력 데이터들이 얼마나 고르게 얼마나 균일하게 존재하냐에 따라 값이 주어지는데 아래의 그림으로 설명하면 불균형하게 분포되어 있는 집단은 high entropy를 가지고 균형 있게 잡힌 집단은 low entropy라고 합니다.

그렇다면 어떻게 entropy가 계산되는지 알아보도록 하겠습니다. 아래의 수식은 모집단 A에 대한 엔트로피를 계산하는 식 입니다.

예를 들어 저희에게 모집단 A는 위 그림에 있는 High entropy라고 했을 때
m -> class의 갯수(ex. 초록색, 빨간색) 2개
k -> class의 순서(ex. k=1(초록), k=2(빨강))
p_k -> k가 나올 확률 (눈을 감고 모집단 A에서 손을 넣어 끄집어낼 때 초록색이 나올 확률은 10/14이고 빨간색이 나올 확률은 4/14입니다.)
이렇게 알아볼 수 있습니다. 그렇다면 수식으로 풀어서 설명해보겠습니다.

High entropy를 가지는 집단의 entropy는 약 0.86이 나왔네요 그렇다면 low entropy에 대한 entropy 또한 계산해보면..

모집단 B 즉, low entropy 집단의 entropy는 0이 나왔습니다. 그렇다면 이 entropy를 가지고 어떻게 쓰냐? 에 대한 생각을 해야 하는데 우리가 알아야 하는 Information Gain은 특정 feature를 거치기 전 데이터의 Entropy와 feature를 거친 후 classifcatione 된 데이터들의 Entropy 합의 차이만큼 이 Information Gain입니다.
말로 표현하기 어려우니 그림과 수식으로 표현하면 아래와 같습니다.

먼저 Feature(A)에 들어가기 전 입력 데이터들에 대한 Entropy를 계산합니다.

Entropy(A) -> Feature A에 들어오는 입력 데이터들의 Entropy
m -> class의 개수(ex. 빨강, 파랑)
p_i -> i번째 class가 나올 확률
위 그림에 대한 예로 Entropy를 계산하면 (i = 1 이 파랑, i = 2 빨강) 입력 데이터에 대한 Entropy는 1이 나옵니다.

입력 데이터가 Feature(A)에 들어가 classification이 되면 아래와 같이 나눠지게 됩니다. 분류된 데이터들은 각각 j = 1, j = 2, j = 3으로 모집단을 형성하게 됩니다.
그리고 classification 된 각각의 데이터들의 entropy를 구한 후 정규화 과정 거친 후 각각의 Entropy의 합을 구해줍니다.

Entropy_F(A) -> Feature A로 분류된 데이터들의 Entropy의 총합계
Entropy(A_j) -> Feature A로 분류된 j번째 데이터들의 Entropy
A_j -> j번째 데이터의 개수
A -> 입력 데이터의 개수
j = 1 일 때의 Entropy_F(A)는

j = 2 일때의 Entropy_F(A)는

j = 3 일때의 Entropy_F(A)는


그렇다면 이제 Information Gain을 구해야 하는데 수식으로 풀면 이렇습니다.



그렇다면 지금 우리는 피쳐 A에 대한 Information Gain을 알았고 이제 이런 방법으로 모든 피쳐에 대한 Information Gain을 구합니다. 그러면 모든 피쳐에 대한 Gain 중 가장 높은 Information Gain을 고르면 가장 classification이 잘 된 피쳐겠지요. 여기까지의 방법은 서두에 이야기했던 3가지 알고리즘 중 ID3 알고리즘에 해당하는 방법입니다. 그렇다면 이제 C4.5 알고리즘에 대해 알아보겠습니다.
C4.5 알고리즘
C4.5 알고리즘은 기존에 ID3 알고리즘의 확장판이라고 생각하시면 됩니다. 기존의 ID3 알고리즘은 치명적인 단점이 존재했습니다. 방금 전까지 예시를 들었던 Feature는 color에 대한 Information Gain에 대해 나눴습니다. 하지만 만약 각 객체마다의 identity가 다양하고 그 identity에 대한 feature 또한 가지각색이면 무수히 많은 classification이 되겠지요. 그림으로 보여드리겠습니다.

만약 이런 식으로 다양한 classification이 되어버리고 각각의 Entropy를 구하여 계산하면 이 Feature가 좋은 Feature일까요? 얼핏 눈으로 보기에는 오히려 아래 그림이 더 좋은 feature로 보입니다. 하지만 각 Feature에 대한 Gain을 구하면 사실 with whom이라는 feature가 더 크게 나오고 windy라는 feature는 더 작은 값을 가지게 됩니다.

그렇기 때문에 이런 불공평성을 없애기 위해 Information Gain Ratio라는 방법을 사용하기 시작했습니다. C4.5 알고리즘에서는 이를 Gain Ratio 혹은 normalization to information gain이라고 부릅니다. Gain Ratio를 구하는 방법은 기존의 방법에서 SplitInfo를 통해 가짓수에 대한 정규화를 가집니다.

Gain(A)를 구하는 방법은 위 과정과 동일하기 때문에 SplitInfo를 구하는 방법에 대해서만 다뤄보겠습니다. 수식은 아래와 같습니다.

Split Info?
The split information value represents the potential information generated by splitting the training data set D into v partitions, corresponding to v outcomes on attribute A.
j = 1 일 때의 splitinfo는

j = 2일 때의 splitinfo는

j = 3일 때의 splitinfo는




이런 식으로 다양하게 분류된 classification에 대한 페널티를 SplitInfo로 Gain에 가함으로써 조금 더 공평한 Gain을 구할 수 있는 것이 C4.5 알고리즘의 특색입니다. 이제 마지막으로 CART 알고리즘에 대해 소개해보겠습니다.
CART 알고리즘
CART 알고리즘은 ID3 알고리즘과 비슷한 시기에 개발된 알고리즘으로 Classification and Regression Tree의 약자입니다. 말 그대로 classification, Regreesion도 가능한 알고리즘인데, 앞서 소개한 ID3와 C4.5 알고리즘들과 몇 가지 차이점이 존재합니다.
차이점 1.
기존에는 입력 데이터와 분기(피쳐)를 지난 후의 Entropy 차를 이용하여 Gain을 구하여 가장 좋은 Feature를 고르는 방식이었다면, 이제는 CART알고리즘에서는 Gini index라는 새로운 개념을 사용하여 좋은 Gini index를 가지 Feature를 찾자!입니다.
Gini index
shares same idea with the entropy
차이점 2.
CART 알고리즘의 또 하나의 특징이자 다른 알고리즘들과의 차이점은 분기 시 즉, classification 된 자식 노드의 개수는 여러 개의 자식 노드가 생기지 않고 단 두 개의 자식 노드로 분기된다는 것입니다.
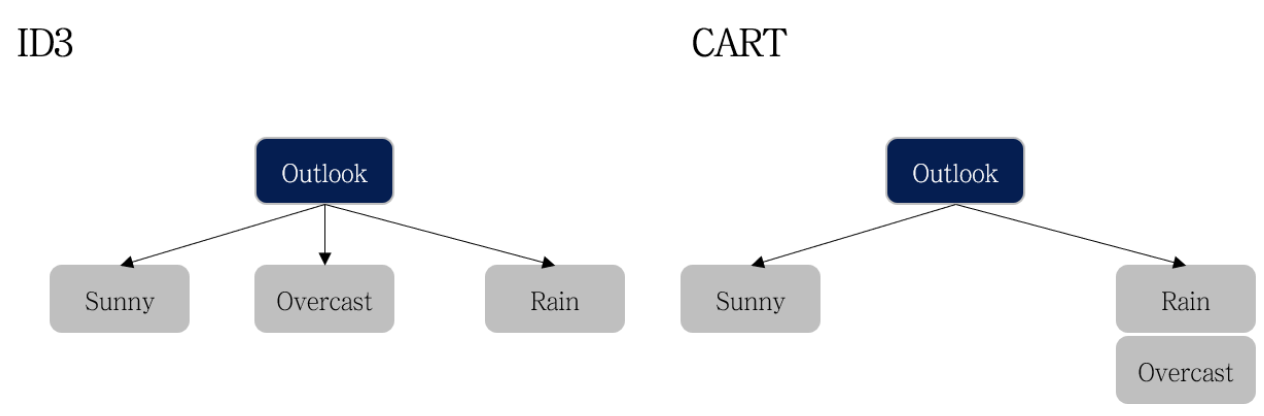
차이점 3.
Gini index는 엔트로피와 같이 classification이 잘 될 때 낮은 값을 갖습니다. 따라서 CART 알고리즘은 모든 Feature에 대한 Gini Index를 계산한 후, 델타 Gini index가 가장 낮은 Feature(좋은 피쳐)를 찾으면 됩니다.
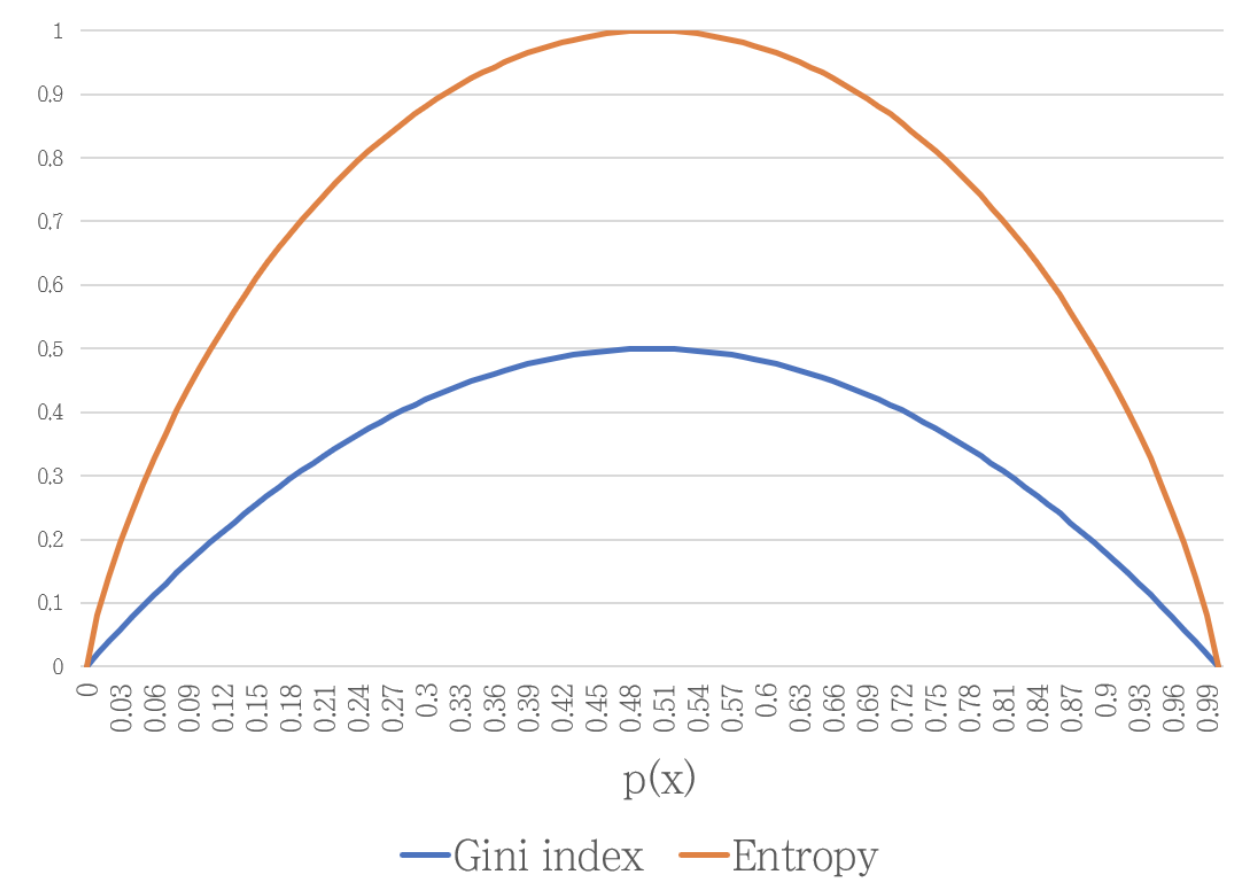
Gini index는 엔트로피와 같이 분류가 잘 될 때 가장 낮은 값을 갖습니다. 따라서 CART 알고리즘에서는



우선 간단한 예시부터 풀어보겠습니다.
먼저 입력 데이터에 대한 gini(D)를 구하고,


이후 분류된 데이터들마다의 gini_A(D)를 구해줍니다. j = 1일 때,
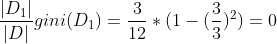
j = 2일 때,

j = 3 일때,
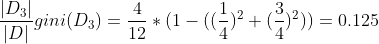




Overfitting of decision tree models
- Too many branches, some may reflect anomalies due to noise or outliers
- Poor accuracy for unseen samples
분기(branch)의 수가 많아지면 많아질수록 tree의 깊이가 깊어지고 입력 데이터에 대한 분류가 잘 이루어지지만 오버 피팅에 대한 이슈가 발생합니다.


Training data에 대해서는 확실하게 error 값을 줄일 수 있지만, 다른 Test data에 대해서는 특정 부근에 과적합으로 인해 오버 핏팅이 발생하여 무조건 branch가 많다고 훌륭한 decision tree라고 할 수 없습니다. 그렇기 때문에 어느 정도의 에러에 대한 타협을 거쳐야 하고 이를 우리는 Tree Pruning을 한다고 합니다.
Tree Pruning
- Pruning can be seens as smooting the decision boundary

해석의 의미 그대로 '가지치기'인데 이를 통하여 우리는 데이터들에 대해 완벽한 classification을 할 수는 없지만 Test data도 훌륭하게 classfication을 할 수 있는 decision tree를 구성하면 됩니다.
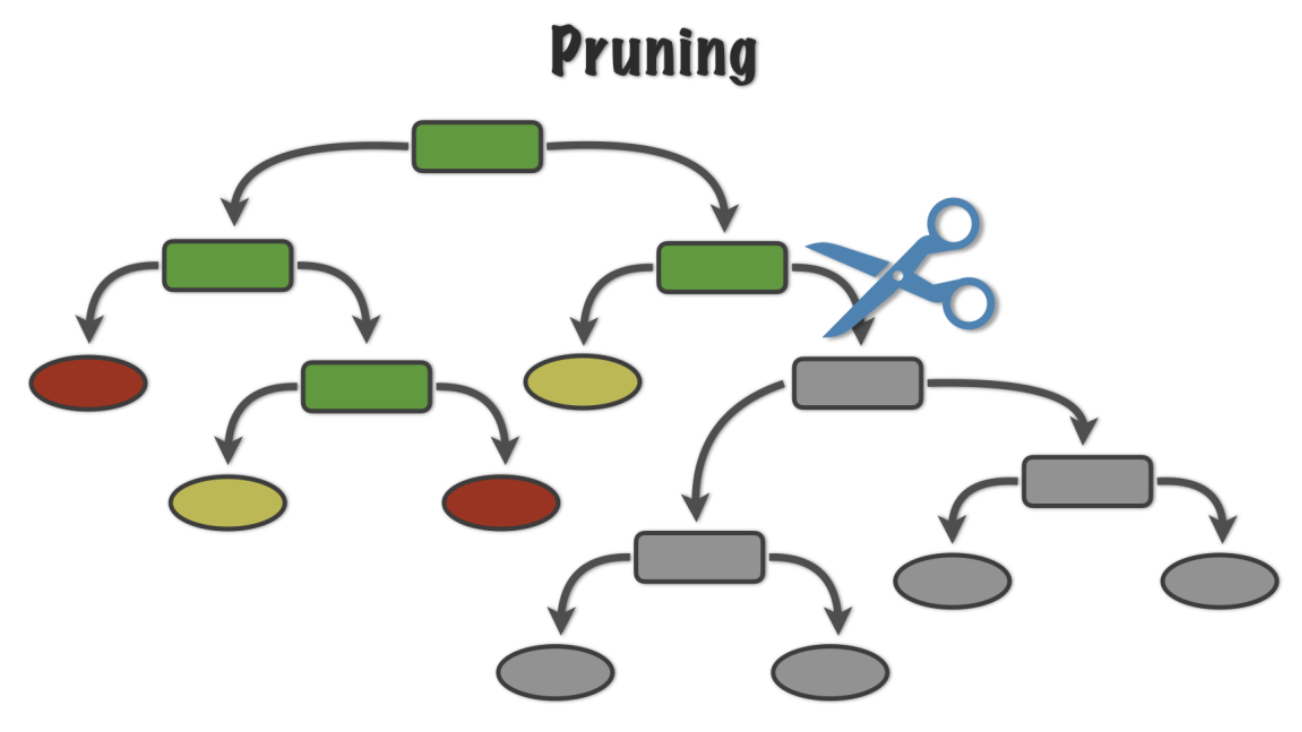
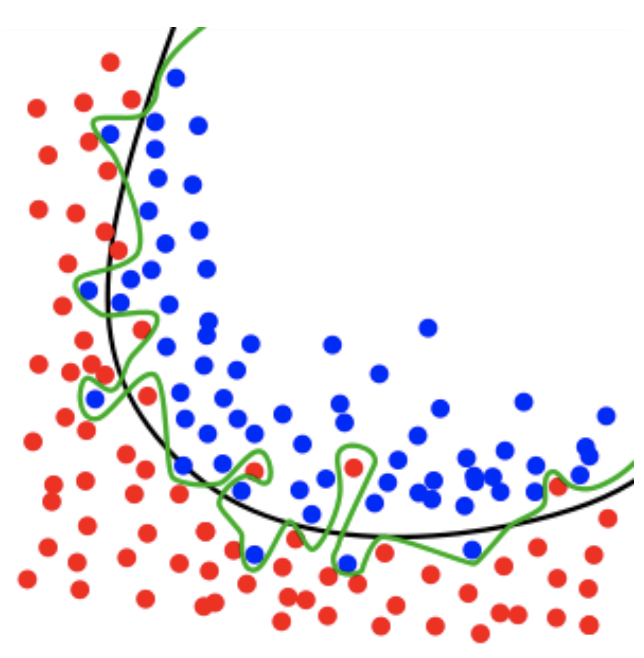
위 그림을 보면 초록색 라인이 Training data를 완벽하게 분류한 부분이지만 검은색 라인은 overfitting을 고려해 어느 정도 오차율을 고려하여 완벽한 분류는 못하지만 Test data에서도 쓸만한 결과를 뽑을 수 있게 해야 합니다. Tree Pruning을 하는 방법은 크게 두 가지가 있는데
Tree Pruning two approaches to avoid overfitting
1. Pre-pruning: Half tree construnction early
2. Post-pruning: Remove branches from a "fully grown" tree
가지치기를 실행하면 학습 데이터에 대한 에러가 발생합니다. 하지만 테스트 데이터에 대한 에러는 감소합니다.
Pre-pruning(선 가지치기)는 두 가지 조건이 있는데,
1. 'Decision tree를 만들 때 branch가 너무 많으면 overfitting이니 구축을 정지해라'
2. 'information Gain, Gini index를 활용하여 Training data error와 Test data error가 비슷하면 overfitting이 아니다'
하지만 이 두 가지 조건의 threshold를 얼마를 줘야 하냐?라는 점이 존재합니다.
Post-pruning(후 가지치기)는 선 가지치기와는 다르게 Decision tree를 완전히 구축한 후에 맨 마지막 브런치부터 차례대로 위로 올라오면서 Training data error와 Test data error를 비교하여 가지치기를 진행합니다.
지금껏 우리는 입력 데이터에 대한 효과적인 분기(feature)를 찾아 트리를 구성하여 효과적인 classification을 이루어내는 Decision tree에 대한 이론과 알고리즘에 대해 설명하였습니다. 하지만, 이런 가지치기를 아무리 한다고 해도 decision tree의 overfitting은 충분히 해결할 수 없습니다. 그러므로 조금 더 효과적인 트리를 만드는 방법을 생각해야 했고, 이는 Random forest의 기원이 되는 아이디어였습니다. 다음 포스트 때 Random forest에 대한 새로운 이야기를 하겠습니다. 긴 글 읽어주셔서 감사합니다.
본 글은 Hanyang University Computer and Software - Dong-Kyu Chae 교수님 수업 자료를 바탕으로 구성하였습니다.
'Machine learning' 카테고리의 다른 글
| Linear Regression (0) | 2021.09.22 |
|---|---|
| Random Forest (0) | 2021.09.20 |
| correlation coefficient (피어슨 상관계수) (0) | 2021.08.24 |
| covariance matrix (공분산 행렬) (0) | 2021.08.21 |
| Linear kalman filter (LKF) (0) | 2021.08.08 |