INTRODUCTION
Classification의 문제는 샘플 공간 X에 존재하는 샘플 {x1, x2,⋯ } ∈ X 각각에 대해서 이 샘플들은 어떤 클래스 y ∈ Y로 분류할 것인가에 관한 문제로 생각할 수 있다. 일반적으로 이러한 문제에 대해 우리는 예로 Classifier f라는 함수를 정의할 수 있다. Classifier f:X⟼Y는 주어진 샘플 공간(X)으로부터 클래스 공간(Y)으로 Mapping 해주는 함수라고 정의할 수 있을 것이다. 예를 들어 여러 애완동물 중(X) 강아지냐 아니냐에 대한 Class((Y={0,1})로 분류하는 Classifier f를 예시로 들어보자 f는 다음과 같아진다.
f(cat) = 0, f(Lion) = 0, f(Welsh Corgi) = 1, f(Pomeranian) = 1
다음 예시로 다른 Classifier g는 다음과 같은 결과가 나올 수도 있다.
g(cat) = 0, g(Lion) = 0, g(Welsh Corgi) = 0, g(Pomeranian) = 1
이 경우 f는 웰시코기에 대해 정확하게 분류를 했지만, g는 그렇지 못하다. 직관적으로 함수의 성능을 비교 평가했을 때 g보다 f가 더 성능이 좋음을 볼 수 있다. 위와 같은 예시로 Optimal classifier를 정의할 수 있다. Optimal classifier의 정의는 다음과 같다.
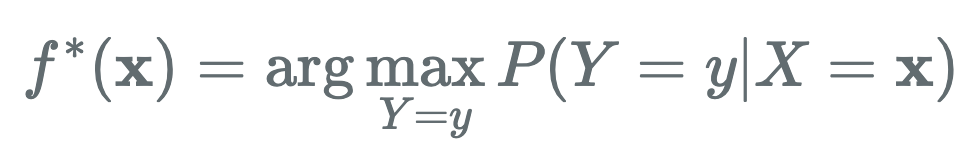
위의 예시로 설명을 해보면, 실제 자연계의 모델은 주어진 X(애완동물들)에 대하여 강아지인지 아닌지에 대한 분포 P(Y | X=x)를 모델링하고 있다고 가정할 수 있다. 이러한 분포를 최대로 만족하는 Classifier f가 바로 우리가 찾고자 하는 Optimal Classifier가 될 것이다. 하지만 우리는 이러한 가정을 어떻게 모델링을 할 것인가?
모델링을 하는 방법은 여러 가지가 있지만 Bayes decision rule을 활용한 예시에 대해 다뤄보도록 하겠다.
Bayes decision rule
A decision rule is a function which maps an observation to an appropriate action. Decision rules play an important role in the theory of statistics and economics, and are closely related to the concept of a strategy in game theory.
(출처: https://en.wikipedia.org/wiki/Decision_rule)
우리는 잉어와 붕어에 대한 Classifier 예시를 들어보고자 한다. 한탄강 안에 존재하는 물고기는 잉어와 붕어만 존재한다. 처음 낚싯대를 던져 물고기를 잡았을 때 잉어가 잡힐 확률과 붕어가 잡힐 확률은 얼마인가? 이때, 우리가 아는 정보는 단지 호수 안에 존재하는 물고기의 분포량이다. 이때 이 정보를 우리는 사전 정보라고 하고 prior information이라고 한다.
(한탄강 안에 존재하는 물고기의 수는 100마리 (잉어 70마리, 붕어 30마리))
Use the prior information

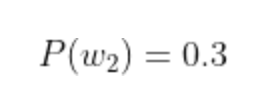
이때 단순히 물고기의 분포량만으로 따졌을 때 첫 낚시를 했을 때 잉어가 나올 확률이 높다.

하지만 여기서 우리는 낚아낸 물고기가 잉어인지 붕어인지 어떻게 분별할 것인가? 이때 우리에게 필요한 건 붕어와 잉어를 분별할 수 있는 특징이다. 이때 두 class를 분류할 수 있는 특징을 정하고 그 특징이 각각의 class에서 나올 확률을 구하는 PDF를 만들어야 한다.
Use the class-conditional information( = likelihood)
지금은 우리가 두 class에 대한 PDF(probability density function)을 알고 있다는 전재하에 이야기를 해보자.
(PDF를 만드는 방법은 다음 글에 나온다..)

간단하게 두 class에 대한 그래프를 도식화하면 이렇다. 그래프에서 (x는 feature), (y는 두 class에서 x가 나올 확률)을 뜻한다. 우리의 feature는 물고기의 길이라고 가정했을 때 예를 들어 처음에 잡은 물고기의 길이가 12cm 라고 했을때 w1이 나올 확률은 어림잡아 0.18, w2가 나올 확률은 0.28로 상대적으로 w1에 비해 높은 확률을 가지고 있다.
지금은 단 하나의 faeture 만으로 PDF를 만들었지만 그렇다면 많은 수의 feature를 사용하면 우리가 찾고자 하는 완벽한 분류를 할 수 있지 않을까?라는 생각을 할 수 있다. 하지만 feature가 추가될수록 PDF의 차원은 기하급수적으로 늘어날 것이다. feature가 많이 지면 classifier가 쉬워지지만 그만큼 차원의 저주가 생기게 된다.
조금 더 수식적으로 접근해보면 w1이 결정된 확률은 P(x|w1) [w1에서 x가 나올 확률] > P(x|w2) [w2에서 x가 나올 확률]이다.
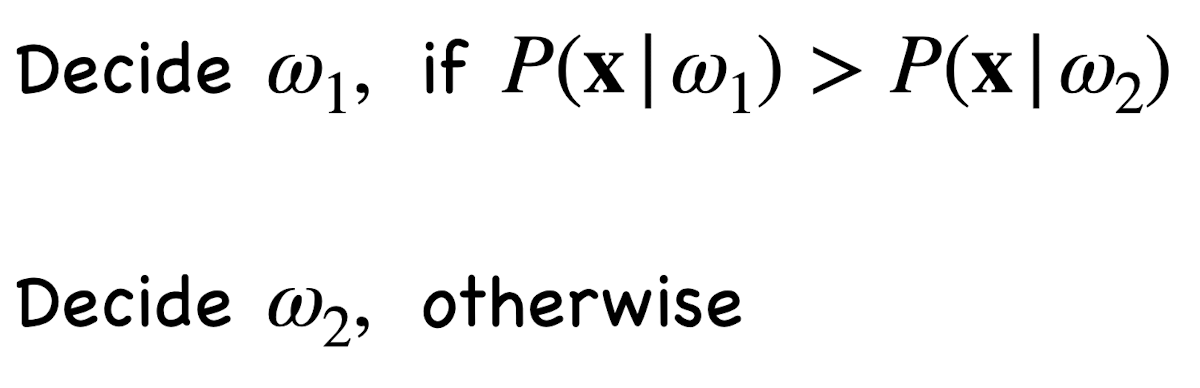
여기서 x(feature 값)는 결국 likelihood(Observation)이다. 그럼 지금까지 우리가 알고 있는 정보는 두 가지이다.
1. 한탄강 안에 물고기의 분포량
2. 물고기의 길이에 따른 잉어일 확률, 붕어일 확률
위 정보들을 사용하여 한탄강에서 낚시를 해서 잡은 물고기의 길이와 우리가 사전에 알고 있는 물고기의 분포량을 적절히 섞은 Posterior를 구해야 한다. Posterior에 대한 수식을 풀면 아래와 같다.
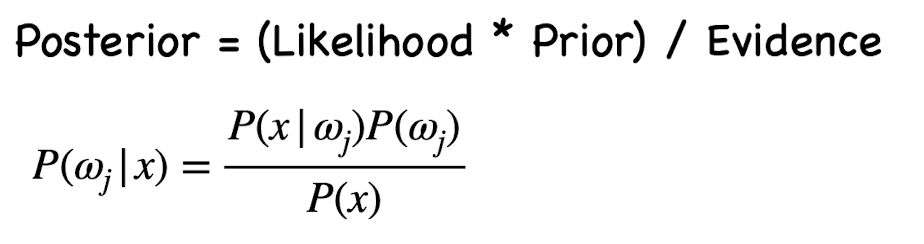
수식적으로 풀어 읽어보면 P(wj | x) = x라는 observation이 나타났을 때 wj가 나올 확률이다. 즉, x가 12일 때 w1일 확률, x가 12일때 w2일 확률을 구할 수 있다.
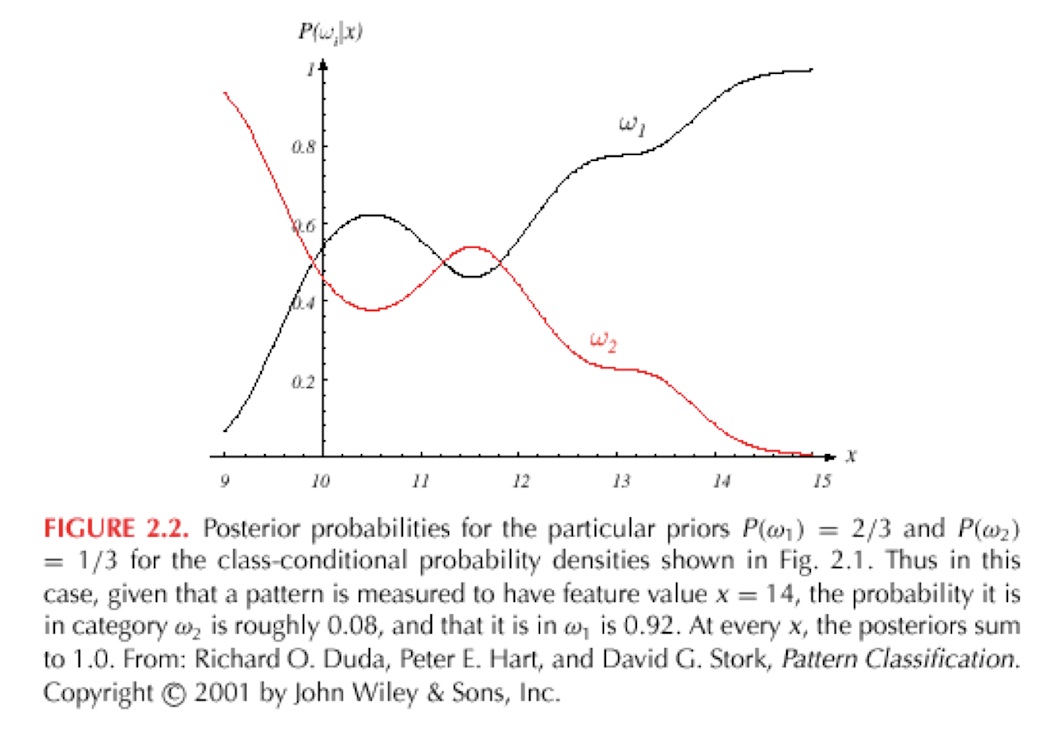
결국 우리가 관측한 observation에 따라 classification을 posterior probabilities가 더 큰 쪽으로 decision 하는 게 bayes decision rule이다. 하지만 여기서 우리는 예시로 한탄강 물고기의 분포량을 알고 있었지만 실제로 우리가 비교하고자 하는 class의 분포량을 찾을 수 없을 수도 있다. 그럴 때는
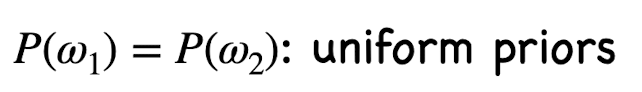
(uniform) 균일하게 두 class의 값을 준다고 한다. ex) w1 = 0.5, w2 = 0.5
위와 같은 방법으로 object classification을 하고 싶을 때 class에 대한 prior, likelihood를 통해 posterior를 예측할 수 있고 확률적으로 가장 큰 posterior 값을 가지는 class에 대해 optimal statistical classifier를 할 수 있다고 한다. decision rule에 대한 정리를 하면 이렇습니다.
- Decision given the posterior probabilities
- Given x as an Observation
- Decide w1, if P(w1 | x) > P(w2 | x)
- Decide w2, otherwise
지금까지의 이야기는 단순히 classification을 하기 위한 이야기였지만, 다음 글부터는 나의 어떤 행동에 의해 지금껏 열심히 계산해온 사후 확률(posterior probabilities)이 바뀔 수 있는 action & loss에 대한 이야기를 해보려고 합니다.
'Machine learning > Optimal statistical calssifier' 카테고리의 다른 글
| Support Vector Machine(SVM) (0) | 2021.10.03 |
|---|---|
| Bayes decision rule - 2 (0) | 2021.07.18 |