Paper : https://arxiv.org/pdf/2004.01888.pdf
Github : https://github.com/ifzhang/FairMOT
ifzhang/FairMOT
A simple baseline for one-shot multi-object tracking - ifzhang/FairMOT
github.com
FairMOT : On the Fairness of Detection and Re-Identification in Multiple Object Tracking
Yifu Zhang∗, Chunyu Wang∗, Xinggang Wang†, Wenjun Zeng, Wenyu Liu
Abstrat
최근 몇 년 동안 다중 객체 추적(MOT)의 핵심 구성 요소인 객체 감지(object detection) 및 재식별(Re-identification)에 대해 집중할 만한 진전이 있었습니다. 하지만 단일 네트워크에서 두 작업을 공동으로 수행하는 데는 거의 관심이 집중되지 않았습니다.
우리의 연구는 이전에 주로 많은 이슈가 되었던 객체의 identification이 변경되는 이유가 Re-identification 작업이 제대로 학습되지 않았기 때문에 발생했다는 것을 알았습니다. 기존의 방식에서 Re-Identification 작업이 제대로 되지 않는 문제점은 두 가지 입니다.
1)Re-ID를 1차 검출 작업(detection)에 따라 정확도가 크게 달라지는 2차 작업으로 구성했습니다.(first. Detection -> second. Re-ID) 따라서, 학습은 대부분 detection작업에 치우쳐 있지만 Re-ID 작업에 대해서는 크게 생각하지 않았습니다.
2) ROI(Region of Interest) 방식을 사용하여 객체 감지에서 직접 Re-ID featrue를 추출합니다. 그러나 ROI 영역에서 샘플링을 진행할 때 ROI 영역 안에 불필요한 instance나 배경이 포함 될 수 있기 때문에 이것은 객체 특성화에 많은 모호성을 가져옵니다. 이런 문제를 해결하기 위해 픽셀 단위 객체성 점수(objectness scores..객체가 있을 확률)와 Re-ID feature를 예측하는 두 개의 균일한 branch로 구성된 간단한 접근 방식 FairMOT를 제시합니다. 작업(task) 간의 공정성을 통해 FairMOT는 높은 수준의 감지 및 추적에 대한 정확성을 얻을 수 있으며 여러 공개 데이터셋에서 이전에 나왔던 기술보다 훨씬 뛰어난 성능을 얻을 수 있습니다.
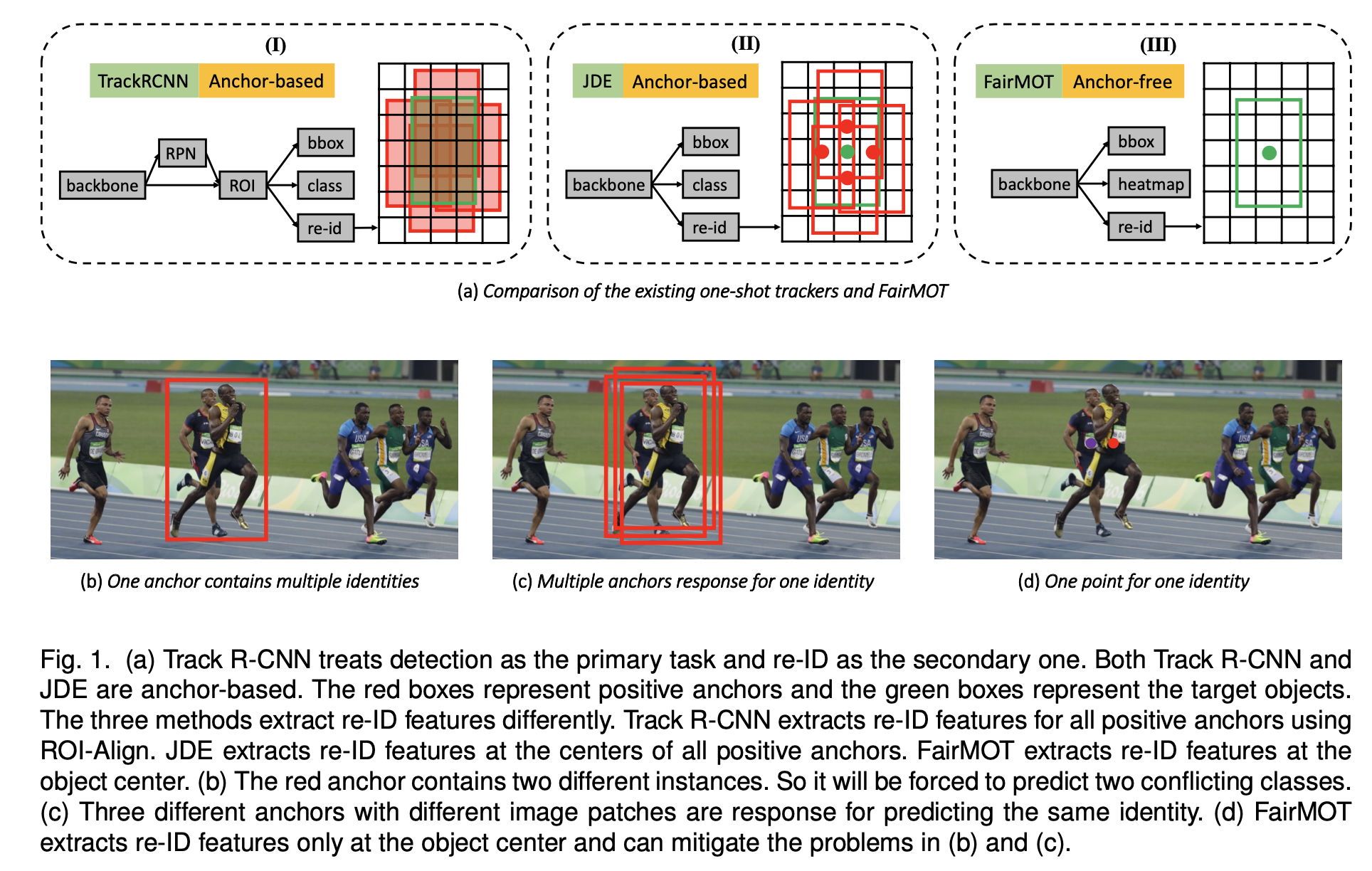
Unfairness Caused by Anchors
현재 One-shot tracker(R-CNN, JDE)들은 모두 객체 탐지 기반이기 때문에 anchor(Bounding) box 기반으로 하고있다. 그러나 본 연구에서는 anchor 기반은 Re–Identification feature에 대해 학습하는데 적합하지 않음을 발견했다.
Anchor?
Anchor 라는 개념은 Faster R-CNN에서 처음으로 제안되었다. Object Detection 문제에서 우리는 이미지 상에 물체(Object)가 있는 영역을 예측하여 Bounding Box(BBox)를 그려야 한다. 이때, 이미지 전체를 한꺼번에 보고 특정 위치를 예측하는 것보다 특정 영역에서만 Box를 보고 이 안에 물체가 있는지를 예측하는 편이 더 쉽기 때문 anchor box가 만들어졌다.
Anchor don`t fit Re-ID
A 객체에 대한 identity를 가지는 anchor box들과 B 객체에 대한 identity를 가지는 anchor box들이 서로 근접해 있을 경우 Re-identification시 서로간에 비슷한 모호성 때문에 신경망에 심각한 문제를 줄 수 있기 때문이다.
Overlooked re-ID task
R-CNN은 먼저 object bounding box를 추정한 다음 re-identification feature를 추정하는 계단식 스타일로 작동한다. 그렇기 때문에 re-identification의 성능은 앞선 bounding box의 성능에 의해 좌우된다. 결국 이런 계단식 학습단계에서 심각한 편파적인 문제 발생한다.
One anchor corresponds to multiple identities
Anchor 기반 방법들은 일반적으로 입력 데이터에서 객체에 대한 feature를 ROI-Pool or ROI-Align을 사용하여 feature map을 추출한다. 하지만 ROI 방법 중 ROI-Pool 방법은 고정된 feature map(ex. 3x3) 크기를 얻을 수 있는 대신 그 축소 과정에서 원본 데이터에 대한 데이터 손실이 발생 할 수 있고, ROI-Align 방법은 그림 1과 같이 대상 객체를 정확하게 추출하는게 아닌 원치 않는 다른 방해 요소(배경) 또한 같이 추출되는 단점이 있다. 결국 추출된 feature들은 우리가 알고자 하는 객체에 대한 최적의 feature가 아니다.
Multiple anchors correspond to one identity
입력 영상 데이터에서 작은 변화라도 일어났을 때 anchor가 근처에 있는 다른 객체 or 배경에 대한 identity를 추정하도록 강요 될 수 있다.
또한, object detection의 feature maps은 정확도와 속도의 균형을 맞추기 위해 보통 8/16/32배까지 하향 샘플링(down sampling) 된다. 물론 object detection에 그럭저럭 허용되는 과정이지만, 이후 Re-identification feature에서 학습을 하기에는 너무 안좋은 데이터(coarse!!)이다.
Unfairness Caused by Features
One-Shot trackers의 경우 대부분의 features은 object detection과 re-ID 작업 간 공유가 된다. 특히, Object detection에서는 객체 클래스 및 위치 추정을 하기 위해 수 많은 feature(feature안에 feature)가 필요하지만 RE-Identification은 동일한 클래스의 instances 단위로 구분하기 위해 low-level의 appearance features에만 초점을 둔다.
Unfairness Caused by Features Dimension
일반적으로 Re-Identification은 매우 높은 차원의 features 들을 학습하면 좋은 결과를 달성한다고 한다. 그러나 다음과 같은 두가지 이유로 본 논문에서는 One Shot MOT에서는 저 차원의 features들을 학습하는 것이 더 낫다는 것을 알게 되었다.
1) high dimensional Re-Identification features 는 확실하게 물체를 구별할 수 있는 능력이 향상 될 수 있지만, Object detection 간의 연계로 인해 물체 감지의 정확도와 속도가 저하되고 최종 추적 정확도에도 부정적인 영향을 가질 수 있다. 그렇기 때문에 두 작업(Object detection & Re-identification)의 균형을 맞추기 위해 low dimensional Re-Identification features를 학습할 것을 제안한다.
2) training data가 적을 경우, low dimensional Re-Identification features는 over-fitting을 줄일 수 있다. training data가 적을 경우, high dimensional Re-Identification features는 over-fitting이 발생 할 수 있다. 일반적으로 MOT의 data-set은 Re-ID data-set 보다 적기 때문에(Re-ID data-set은 잘린 이미지만 제공 하기 때문에 데이터 양이 많다) lower-dimensional feature를 사용하면 small data들에 대한 overfitting을 줄이고, tracking robustness를 향상 시킬 수 있다.


Overview of FairMOT
본 연구에서는 세 가지 문제들을 한꺼번에 해결하는 “FairMOT”라는 간단한 접근 방식을 제안한다. 기존에 있어 사용되는 First, Detection Second, Re-identification 과정이 아닌 Parallel하게 Detection & Re-identification 작업이 동일하게 처리되기 때문에 이전의 프레임워크들과 근본적으로 다르다.
우리의 contributions은 세가지이다.
1)그동안 묵인되어 왔던 성능을 심각하게 만드는 이전의 One-shot tracking frameworks에 대해 논의하고
2)기존에 anchor 기반의 object detection methods 보다 훨씬 뛰어난 anchor-free 방식의 frameworks를 도입한다.
3)마지막으로, large scale detection datasets에 대해 FairMOT의 효과적인 Supervised learning 학습 접근법을 제시한다.
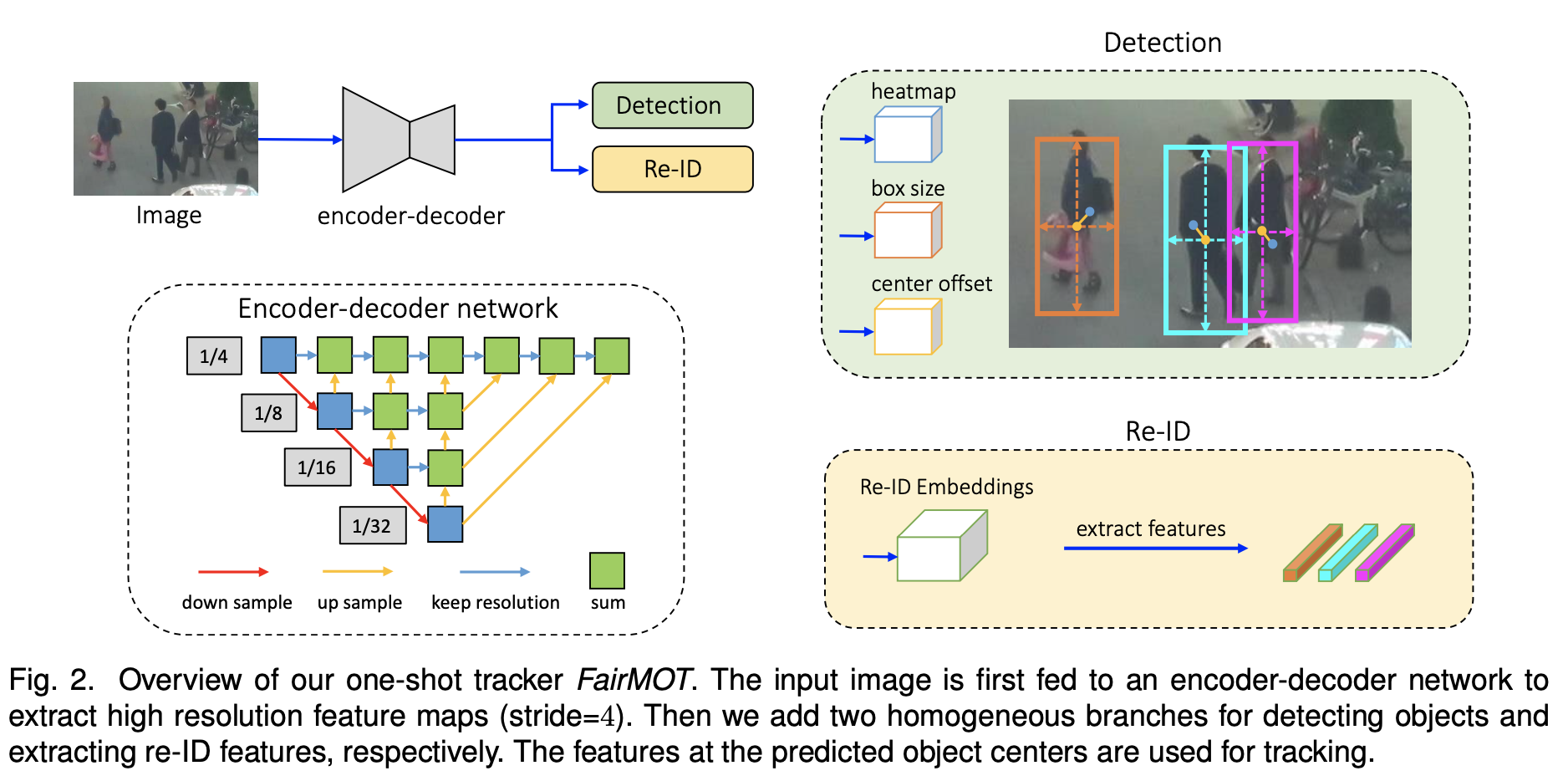
Backbone Network
정확성과 속도 사이의 균형을 잘 맞추기 위해 ResNet-34 (34개의 conv layer)를 딥러닝 모델(Backbone)으로 채택했고,
위 그림처럼 다중 계층을 융합하기 위해 ResNet-34 보다 좀 더 향상된 버전의 DLA-34(Deep Layer Aggregation)가 적용되었다
이 모델은 입력 이미지의 크기를 H x W 라고 하면 output feature map의 모양은 C x H` x W` 이며, 이때 H`는 H/4 이며, W`는 W/4 이다. (C = 34) original DLA와는 달리, Feature Pyramid Network(FPN) 와 유사한 low-level 및 high-level feature 간에 더 많은 skip connection 이 존재한다. 또한, up sampling 과정에서 모든 컨볼루션 레이어들은 deformable convolution layer로 대체되어 객체의 유동적 변화 및 포즈에 따라 receptive field(filter 혹은 커널)를 동적으로 조정 할 수 있다.
Object Detection Branch
객체 탐지는 high-resolution feature map에서 center-based의 bounding box regression task를 수행한다. 우리의 Detection branch는 Center Net 기반으로 설계되었지만, anchor-free method 또한 사용되었다. 특히, 3개의 Parallel regression head가 3개 추가되어 object에 대한 [heat map], [center offset], [bounding box size]를 추정한다. 각 head는 DLA-34 output feature에 대해 3x3 conv(256 channel을 가지는) 후 head에 대한 1x1 conv하여 최종 target을 구한다.
heatmap
head 는 객체 중심의 위치를 추정한다. landmark point estimation task 의 표준인 heatmap 기반 representation 이 여기서 사용된다. 특히 heatmap 의 dimension 은 1 x H x W 이다. heatmap 의 위치에 대한 response 는 ground-truth object center 로 붕괴될 경우의 반응으로 예상된다. heatmap 의 위치와 object center 사이의 거리에 따라 response 는 기하 급수적으로 감소한다.
Center offset
head 는 객체를 보다 정확하게 localization 한다. feature map 의 stride 는 non-negligible quantization error 를 유발할 수 있다. 객체 탐지의 성능의 이점은 미미할 수 있으나, Re-ID 의 특징은 정확하게 object center 에 따라 추출되어야 함으로 tracking 에서는 중요하다는 특징을 가진다. 실험에서 Re-ID 의 특징을 object center 와 carefull alignment 하는 것이 성능에 중요하다는 것을 발견하였다.
Box size
이는 각 anchor 위치에서 target bounding box 의 높이와 너비를 추정한다. 이 head 는 Re-ID 특징과는 직접적인 관련이 없지만, localization 정확도는 객체 탐지 성능 평가에 영향을 미친다.
Re-ID Branch
Re-ID Embeddings의 목적은 객체간의 class 구별을 할 수 있는 feature를 생성하는 것이다. 이상적인 상황에서 서로 다른 객체 사이의 거리가 멀어야 한다. 하지만 서로 다른 객체간의 거리가 가까울 수 있으니 각 객체의 위치에 대한 identity embedding feature를 추출한다. Output feature map인 E는 128 x W x H 영역에 포함되며, Re-ID feature인 x, y에서는 E는 128에 속하고, 객체의 x, y는 feature map에서 추출된다. 본 논문에서는 object identity embeddings을 classification task로 둔다. 특히 학습 데이터 세트에서 same identity의 모든 instance는 하나의 클래스로 취급된다. 이미지의 각 GT box b에 대해 heatmap에서 객체 중심 좌표를 얻는다. 그러면 그 위치에서 identity feature vector를 추출하여 class distribution vector p(k)에 매핑하는 방법을 학습 할 수 있다. GT class label을 one-hot representation 방식으로 Li(k)로 표시한다. 그 다음 softmax를 사용하여 identity loss를 다음과 같이 계산한다.
Loss function
heatmap loss

offset and Box size loss


Identity embedding Loss

Online Tracking
Network Inference
신경망은 1088 x 608 크기의 이미지를 입력으로 넣는다.예측된 Heatmap에서 Heatmap score 기반으로 NMS(Non-Maximun Suppression)을 적용하여 Heatmaps중에서의 peak keypoint를 추출한다. Heatmap score가 임계값보다 큰 경우 keypoint의 위치를 유지한다. 그 다음 추정된 offset과 box의 크기를 기반으로 bounding box를 계산한다. 또한 추정된 object center에서 identity embedding을 추출한다.
Online Association
표준 온라인 추적 알고리즘을 따라 상자를 연결합니다. 먼저 첫 번째 프레임에서 추정된 상자에 기반하여 다수의 tracklet을 초기화합니다.
그런 다음, 이후 프레임에서 Re-ID feature에서 계산한 코사인 거리에 따라 검출된 상자를 기존 tracklet에 연결하고, 초당 일치로 해당 상자를 겹칩니다. 또한 Kalman 필터를 사용하여 현재 프레임에서 tracklet의 위치를 예측합니다. Linked Detection과 거리가 너무 먼 경우, 검출과 큰 움직임을 효과적으로 연결할 수 없도록 해당 비용을 무한대로 설정합니다.
Experiments
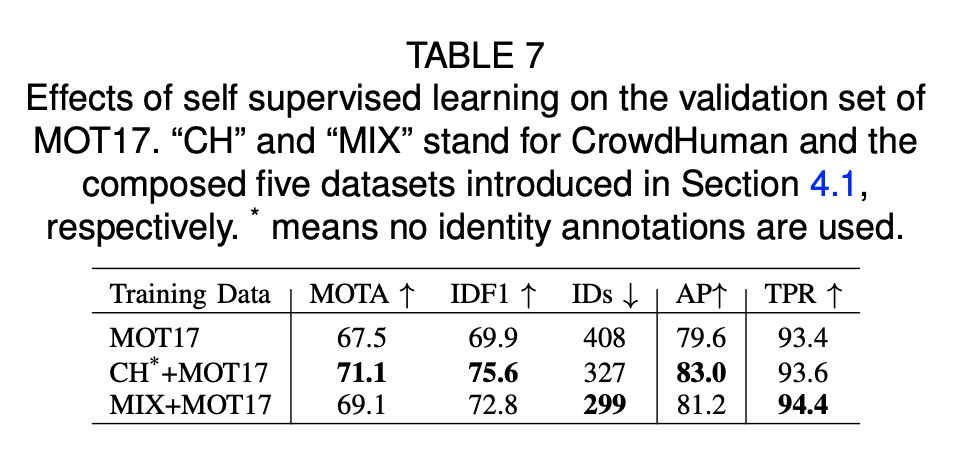
Self-supervised Learning
먼저 CrowndHuman dataset에 대해 FairMOT를 사전 교육을 한다. 특히, 우리는 섹션 3.4(Training FairMOT)에 설명된 방법을 사용하여 각 경계 상자에 대한 고유한 ID 라벨을 할당하고 FairMOT를 훈련시킨다. 그런 다음 target dataset MOT17에서 사전 교육된 모델을 미세 조정한다. 표 7은 그 결과를 보여준다. 첫째, Crowd Human에 대한 self-supervised learning을 통한 사전 교육은 MOT17 데이터 세트에 대한 directly training 결과보다 큰 폭으로 높다. 둘째, self-supervised learning model은 심지어 “MIX” 및 MOT17 데이터 세트에 대해 교육된 fully supervised model보다 우수하다.
Results on MOTChallenge
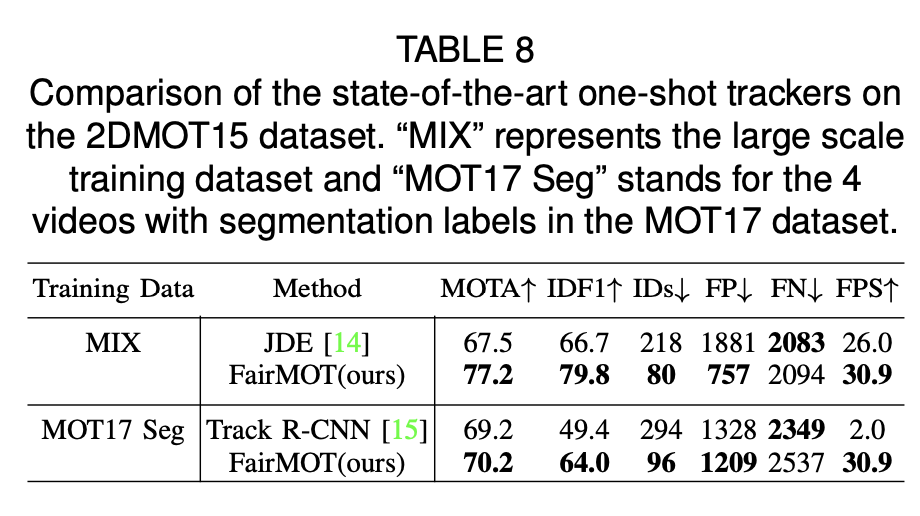
Comparing with One-Shot SOTA MOT Methods
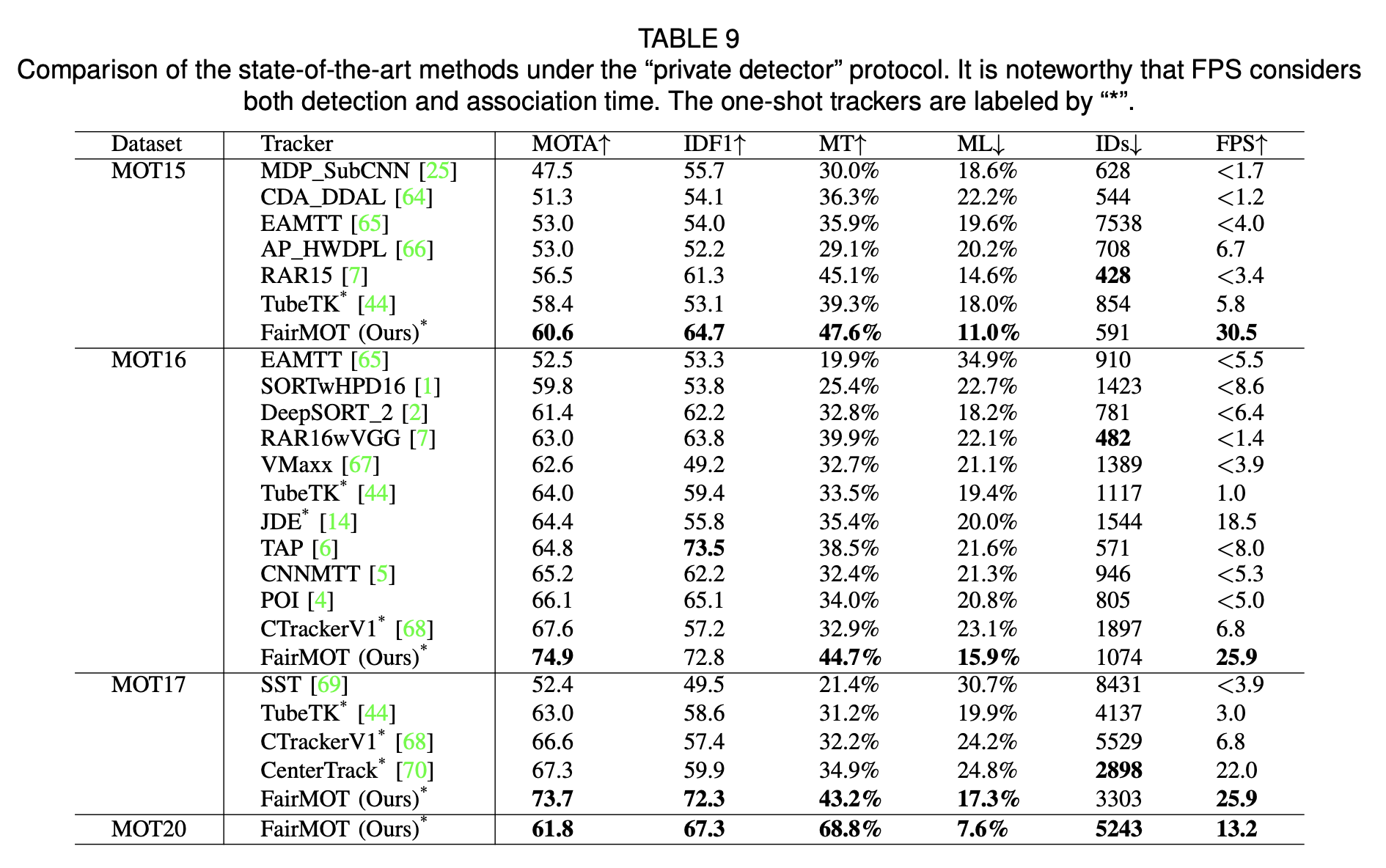
Comparing with Two-Step SOTA MOT Methods

Conclusion
이전에 single-shot 방법들이 2단계 과정(Re-ID)에서 object 간 원활한 비교 결과를 얻지 못하는 이유에 대해 연구를 시작하여, 물체 감지 및 identity embedding 과정에 anchor를 사용하는 것이 성능 저하의 주요 원인임을 알게 되었다. 특히, 객체의 다른 부분에 해당하는 다수의 인근 anchor가 network 교육을 애매하게 만들기도 했다. 또한, 기존 MOT Framework에서 detection과 Re-identification 작업간의 feature 문제를 발견했다. Anchor-free single-shot deep network에서 이러한 문제를 해결함으로써 FairMOT를 제안한다. 추적 정확도와 추론 속도 측면에서 여러 벤치마크 데이터셋의 이전 방법들보다 큰 차이를 보인다. 게다가, FairMOT는 본질적으로 효율적인 데이터 훈련이며, 우리는 Bounding box annotated images만을 사용하여 MOT의 self-supervised training을 제안하며, 이는 우리의 방법을 실제 어플리케이션에서 더 매력적으로 만든다.
'Paper Review' 카테고리의 다른 글
| Automatic Docking and Charging of Mobile Robot Based on Laser Measurement (0) | 2021.11.01 |
|---|---|
| Object Tracking from Laser Scanned Dataset (0) | 2021.10.03 |